
이 포스트는 subicura 님의 kubenetes 안내서을 읽으며 요약/기록한 게시글입니다.
Kubenetes 실습
Pod 생성하기
YAML로 설정파일 작성하여 생성하기
1
2
3
4
5
6
7
8
9
10
apiVersion: v1
kind: Pod
metadata:
name: echo
labels:
app: echo
spec:
containers:
- name: app
image: ghcr.io/subicura/echo:v1
| 정의 | 설명 | 예 |
|---|---|---|
| apiVersion | API 서버 버전 | v1, app/v1, autoscaling/v1 |
| kind | 종류 | Pod, ReplicaSet, Deployment, Service |
| metadata | 메타데이터 | name과 label, annotation으로 구성 |
| spec | 상세명세 | 리소스 종류마다 다름. |
apiVersion, kind, metadata, spec은 리소스를 정의할 때 반드시 필요한 요소이다.
apiVersion은 API 서버의 버전을 나타내는 필드로, apiVersion에 따라 지원하는 리소스가 달라 주의해야한다. 어떤 버전을 사용해야하는지 궁금하면 이 게시글을 참고하자.
위 YAML 파일을 작성하고 다음과 같이 테스트해볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Pod 생성
kubectl apply -f echo-pod.yml
# Pod 목록 조회
kubectl get pod
# Pod 로그 확인
kubectl logs echo
kubectl logs -f echo
# Pod 컨테이너 접속
kubectl exec -it echo -- sh
# ls
# ps
# exit
# Pod 제거
kubectl delete -f echo-pod.yml
컨테이너 상태 모니터링
컨테이너 실행과 실제 서비스 준비는 약간 차이가 있다. 서버를 실행하고 초기화를 거친다음 실제로 접속이 가능할 때 서비스가 준비되었다고 한다.
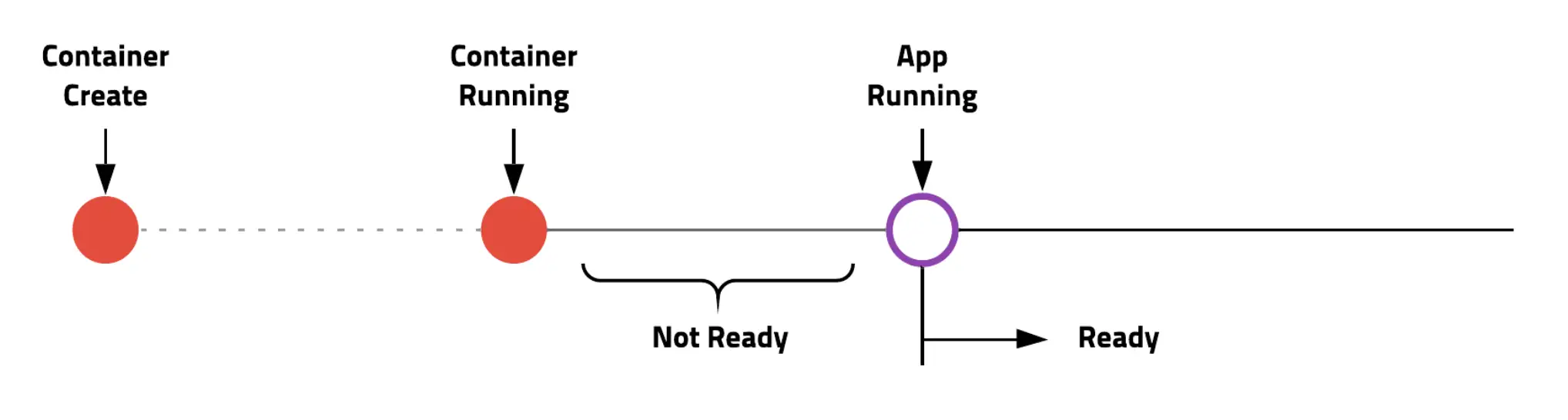
쿠버네티스는 libenessProbe와 readnessProbe로 컨테이너생성과 서비스 준비를 체크하여 초기화하는 동안 서비스 되는 것을 막을 수 있다. 보통은 둘을 동시에 적용한다.
livenessProbe
livenessProbe는 컨테이너가 정상적으로 동작하는지 체크하고 정상적으로 동작하지 않는다면 컨테이너를 재시작하여 문제를 해결한다. 정상상태인지 체크하는 방식에는 여러 가지가 있는데, http get으로 확인하는 방법은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: v1
kind: Pod
metadata:
name: echo-lp
labels:
app: echo
spec:
containers:
- name: app
image: ghcr.io/subicura/echo:v1
livenessProbe:
httpGet:
path: /not/exist
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 2 # Default 1
periodSeconds: 5 # Defaults 10
failureThreshold: 1 # Defaults 3
위 예시는 존재하지 않는 path와 port를 입력하여 일부러 실패에 이르게 하였다. kubectl apply로 pod을 생성하고 시간이 지난 후 kubectl get pod을 통해 pod의 상태를 확인하면 CrashLoopBackOff 상태에 빠진 것을 알 수 있다.
http get이외에도 exec, tcpSocket방법으로도 확인이 가능하다
readinessProbe
readinessProbe는 컨테이너가 준비되었는지 체크하고 정상적으로 준비되지 않았다면 pod으로 들어오는 요청을 제외한다. livenessProbe와의 차이점은 문제가 있어도 pod을 재시작하지 않고 pod으로 오는 요청만 제외한다는 점이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: v1
kind: Pod
metadata:
name: echo-rp
labels:
app: echo
spec:
containers:
- name: app
image: ghcr.io/subicura/echo:v1
readinessProbe:
httpGet:
path: /not/exist
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 2 # Default 1
periodSeconds: 5 # Defaults 10
failureThreshold: 1 # Defaults 3
livenessProbe와 똑같이 존재하지않는 곳으로 요청을 보냈지만, CrashLoopBackOff에는 빠지지 않고 pod의 READY 상태만 0/1로 유지된다.
livenessProbe + readinessProbe
보통은 둘을 함께 적용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: v1
kind: Pod
metadata:
name: echo-health
labels:
app: echo
spec:
containers:
- name: app
image: ghcr.io/subicura/echo:v1
livenessProbe:
httpGet:
path: /
port: 3000
readinessProbe:
httpGet:
path: /
port: 3000
정상적으로 생성된다.
다중 컨테이너
하나의 pod에는 여러개의 컨테이너를 가질 수도 있다. 하나의 Pod에 속한 컨테이너는 서로 네트워크를 localhost로 공유하고 동일한 디렉터리를 공유할 수 있다.
서로 네트워크를 localhost로 공유할 수 있는 이유는 Pod 안의 모든 네트워크는 동일한 IPC namespace 아래에서 시행되기 때문이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
app: counter
spec:
containers:
- name: app
image: ghcr.io/subicura/counter:latest
env:
- name: REDIS_HOST
value: "localhost"
- name: db
image: redis
요청횟수를 redis에 저장하는 웹 어플리케이션이다. 다음과 같이 테스트할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Pod 생성
kubectl apply -f counter-pod-redis.yml
# Pod 목록 조회
kubectl get pod
# Pod 로그 확인
kubectl logs counter # 오류 발생 (컨테이너 지정 필요)
kubectl logs counter app
kubectl logs counter db
# Pod의 app컨테이너 접속
kubectl exec -it counter -c app -- sh
# curl localhost:3000
# curl localhost:3000
# telnet localhost 6379
dbsize
KEYS *
GET count
quit
# Pod 제거
kubectl delete -f counter-pod-redis.yml
현재틑 터미널로 테스트하였지만, Service를 적용하면 브라우저 테스트를 할 수 있다.
ReplicaSet
pod을 단독으로 만들면 pod에 어떤 문제가 생겼을 때 자동으로 복구되지않는다. 이러한 pod을 정해진 만큼 복제하고 관리하는 것이 ReplicaSet이다.
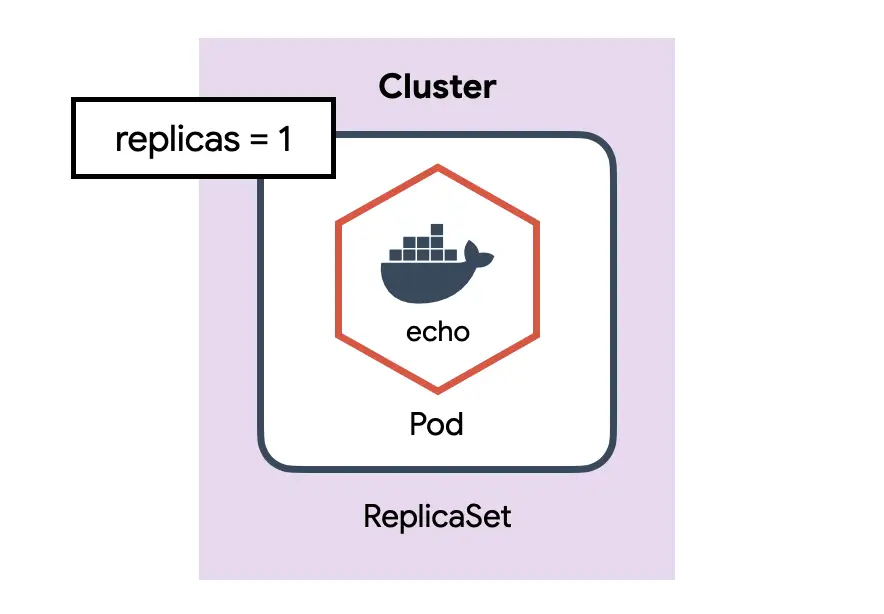
ReplicaSet 만들기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: echo-rs
spec:
replicas: 1
selector:
matchLabels:
app: echo
tier: app
template:
metadata:
labels:
app: echo
tier: app
spec:
containers:
- name: echo
image: ghcr.io/subicura/echo:v1
| 정의 | 설명 |
|---|---|
| spec.selector | label 체크 조건 |
| spec.replicas | 원하는 pod의 개수 |
| spec.template | 생성할 pod의 명세 |
RepliacaSet은 label을 체크해서 원하는 수의 Pod이 없으면 새로운 Pod을 생성한다.
다음과 같이 테스트 가능하다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# ReplicaSet 생성
kubectl apply -f echo-rs.yml
# 리소스 확인
kubectl get po,rs
# 생성한 pod의 label을 확인
kubectl get pod --show-labels
# app- 를 지정하면 app label을 제거
kubectl label pod/echo-rs-tcdwj app-
# 다시 Pod 확인 -> label을 삭제한 pod은 그대로 있고, label과 일치하는 pod이 새로 생김
kubectl get pod --show-labels
# app=으로 라벨 추가
kubectl label pod/echo-rs-tcdwj app=echo
# 다시 Pod 확인 -> 새로 생성된 pod이 제거됨.
kubectl get pod --show-labels
ReplicaSet은 다음과 같이 동작한다.
ReplicaSet Controller는 ReplicaSet조건을 감시하면서 현재 상태와 원하는 상태가 다른 것을 체크ReplicaSet Controller가 원하는 상태가 되도록Pod을 생성하거나 제거Scheduler는 API서버를 감시하면서 할당되지 않은 unassignedPod이 있는지 체크Scheduler는 할당되지 않은 새로운Pod을 감지하고 적절한노드node에 배치- 이후 노드는 기존대로 동작
주의
ReplicaSet은 원하는 개수의 Pod을 유지하는 역할을 담당한다. label을 이용하여 Pod을 체크하므로 label이 겹치지 않게 신경써서 정의해야한다.
실전에서 ReplicaSet을 단독으로 쓰는 경우는 거의 없다. Deployment가 ReplicaSet을 이용하고,주로 Deployment를 이용한다.
Deployment
하나의 배포판을 의미하는 것으로, 쿠버네티스에서 가장 널리 사용되는 오브젝트이다. ReplicaSet을 이용하여 Pod을 업데이트하고 이력을 관리하여 롤백하거나 특정버전으로 돌아갈 수 있다.
Deployment 만들기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-deploy
spec:
replicas: 4
selector:
matchLabels:
app: echo
tier: app
template:
metadata:
labels:
app: echo
tier: app
spec:
containers:
- name: echo
image: ghcr.io/subicura/echo:v1
kind와 metadate.name을 제외하곤 ReplicaSet과 동일한 설정이다.
다음과 같이 테스트 가능하다
1
2
3
4
5
# Deployment 생성
kubectl apply -f echo-deployment.yml
# 리소스 확인
kubectl get po,rs,deploy
한번 위 yml 파일의 spec.template.spec.containers[0].image를 다음과 같이 변경하고 다시 Deployment를 생성해보자
1
2
...
image: ghcr.io/subicura/echo:v2
kubectl get po,rs,deploy 명령어로 확인해보면, 새로운 ReplicaSet이 생기고 Pod이 업데이트되는 것을 확인할 수 있다.
Deployment는 새로운 이미지로 업데이트하기 위해 ReplicaSet을 이용한다. 버전을 업데이트하면 새로운 ReplicaSet을 생성하고 해당 ReplicaSet이 새로운 버전의 Pod을 생성한다. 이때 다음과 같은 과정을 거친다.
- 새로운 ReplicaSet을 0 -> 1개로 조정하고 정상적으로 Pod이 동작하면 기존 ReplicaSet을 4 -> 3개로 조정한다.
- 1을 기존 ReplicaSet이 0개가 될 때까지 반복한다.
- 기존 ReplicaSet을 제거한다.
API 서버와의 통신과정은 다음과 같다.
Deployment Controller는 Deployment 조건을 감시하면서 현재 상태와 원하는 상태가 다른 것을 체크Deployment Controller가 원하는 상태가 되도록ReplicaSet설정ReplicaSet Controller는 ReplicaSet 조건을 감시하면서 현재 상태와 원하는 상태가 다른 것을 체크ReplicaSet Controller가 원하는 상태가 되도록Pod을 생성하거나 제거Scheduler는 API서버를 감시하면서 할당되지 않은 unassignedPod이 있는지 체크Scheduler는 할당되지 않은 새로운Pod을 감지하고 적절한노드에 배치- 이후 노드는 기존대로 동작
버전관리
deployment는 변경된 상태를 기록한다
1
2
3
4
5
6
7
8
9
10
11
# 히스토리 확인
kubectl rollout history deploy/echo-deploy
# revision 1 히스토리 상세 확인
kubectl rollout history deploy/echo-deploy --revision=1
# 바로 전으로 롤백
kubectl rollout undo deploy/echo-deploy
# 특정 버전으로 롤백
kubectl rollout undo deploy/echo-deploy --to-revision=2
배포전략 설정
Deployment엔 다양한 배포 전략이 있다. 여기선 롤링 업데이트(RollingUpdate) 방식을 사용할 때 동시에 업데이트하는 Pod의 개수를 변경해보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-deploy-st
spec:
replicas: 4
selector:
matchLabels:
app: echo
tier: app
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 3
maxUnavailable: 3
template:
metadata:
labels:
app: echo
tier: app
spec:
containers:
- name: echo
image: ghcr.io/subicura/echo:v1
livenessProbe:
httpGet:
path: /
port: 3000
다음과 같이 테스트해보면,
1
2
3
4
5
6
7
8
kubectl apply -f echo-strategy.yml
kubectl get po,rs,deploy
# 이미지 변경 (명령어로)
kubectl set image deploy/echo-deploy-st echo=ghcr.io/subicura/echo:v2
# 이벤트 확인
kubectl describe deploy/echo-deploy-st
Pod을 하나씩 생성하지 않고, 한번에 3개가 생성된 것을 확인할 수 있다.
Deployment는 가장 흔하게 사용하는 배포방식이다. 이외에 StatefulSet, DaemonSet, CronJob, Job등이 있지만 사용법은 크게 다르지 않다.
Service
Pod을 자체 IP를 가지고 다른 Pod과 통신할 수 있다. 하지만 쉽게 사라지고 생성되며 그 과정에서 Pod의 IP가 변경되기에 직접 통신하는 방법은 권장하지 않는다.
쿠버네티스는 Pod과 직접 통신하는 대신 별도의 고정된 IP를 가진 서비스를 만들고, 그 서비스를 통해 Pod에 접근한다.
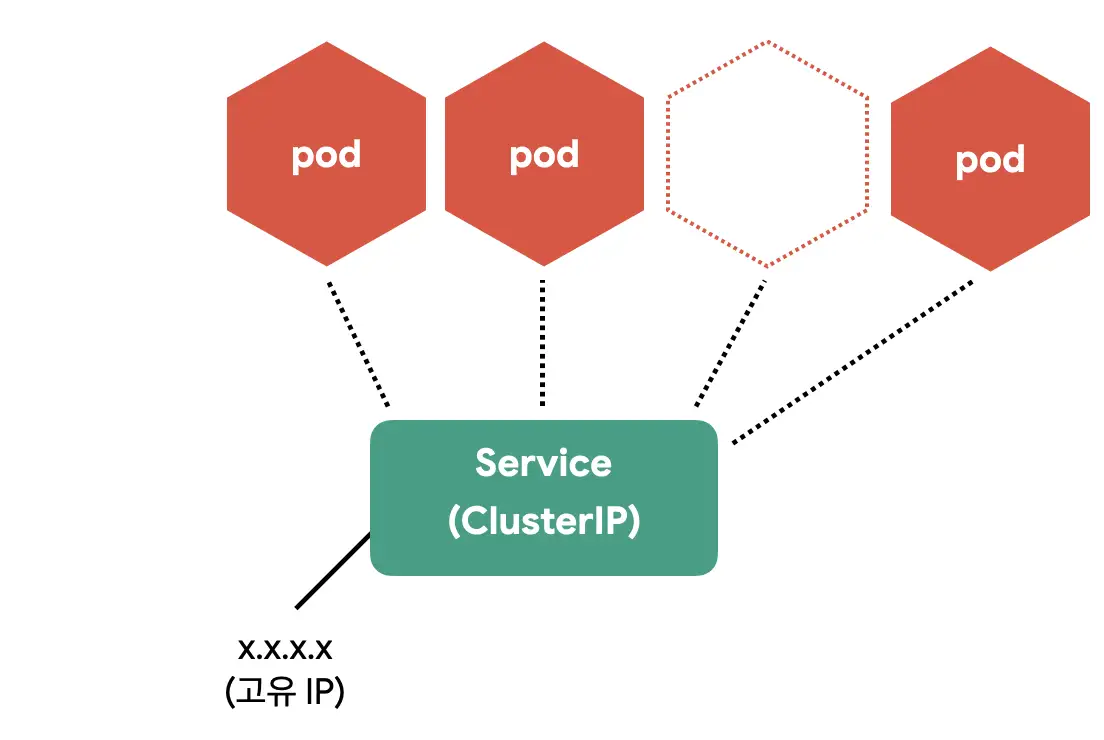
Service(ClusterIP) 만들기
ClusterIP는 클러스터 내부에 새로운 IP를 할당하고 여러 개의 Pod을 바라보는 로드밸런서 기능을 제공한다.
서비스 이름을 내부 도메인 서버에 등록하여 Pod 간에 서비스 이름으로 통신할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
selector:
matchLabels:
app: counter
tier: db
template:
metadata:
labels:
app: counter
tier: db
spec:
containers:
- name: redis
image: redis
ports:
- containerPort: 6379
protocol: TCP
# 하나의 yaml 파일에 여러개의 리소스를 정의할 땐 "---"를 구분자로 사용한다.
---
apiVersion: v1
kind: Service
metadata:
name: redis
spec:
ports:
- port: 6379
protocol: TCP
selector:
app: counter
tier: db
다음과 같이 테스트하면, redis라는 이름의 서비스가 생성되었음을 알 수 있다.
1
2
3
4
kubectl apply -f counter-redis-svc.yml
# Pod, ReplicaSet, Deployment, Service 상태 확인
kubectl get all
같은 클러스터에서 생성된 Pod이라면 redis라는 도메인으로 redis Pod에 접근할 수 있다.
ClusterIP 서비스의 설정은 다음과 같다
| 정의 | 설명 |
|---|---|
| spec.ports.port | 서비스가 생성할 Port |
| spec.ports.targetPort | 서비스가 접근할 Pod의 Port(디폴트 : port와 동일) |
| spec.selector | 서비스가 접근할 Pod의 label 조건 |
이제 redis에 접근할 counter앱을 Deployment로 만들어보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
apiVersion: apps/v1
kind: Deployment
metadata:
name: counter
spec:
selector:
matchLabels:
app: counter
tier: app
template:
metadata:
labels:
app: counter
tier: app
spec:
containers:
- name: counter
image: ghcr.io/subicura/counter:latest
env:
- name: REDIS_HOST
value: "redis" # redis 도메인으로 접근
- name: REDIS_PORT
value: "6379"
다음과 같이 테스트할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
kubectl apply -f counter-app.yml
# counter app에 접근
kubectl get po
kubectl exec -it counter-<xxxxx> -- sh
# curl localhost:3000
# curl localhost:3000
# telnet redis 6379
dbsize
KEYS *
GET count
quit
Service 생성 흐름
서비스는 각 pod을 바라보는 로드밸런서 역할을 하면서 내부 도메인서버에 새로운 도메인을 생성한다.
서비스는 다음과 같이 동작한다
Endpoint Controller는Service와Pod을 감시하면서 조건에 맞는 Pod의 IP를 수집Endpoint Controller가 수집한 IP를 가지고Endpoint생성Kube-Proxy는Endpoint변화를 감시하고 노드의 iptables을 설정CoreDNS는Service를 감시하고 서비스 이름과 IP를CoreDNS에 추가
iptables은 커널 레벨의 네트워크 도구이고, CoreDNS는 빠르고 편리하게 사용할 수 있는 클러스터 내부용 도메인 네임 서버이다. iptables 설정으로 여러 IP에 트래픽을 전달하고, CoreDNS를 이용하여 IP 대신 도메인 이름을 사용한다.
iptables 는 규칙이 많아지면 성능이 느려지는 이슈가 있어, ipvs를 사용하는 옵션도 있다
CoreDNS는 클러스터에서 호환성을 위해 kube-dns라는 이름으로 생성된다.
Endpoint는 서비스의 접속 정보를 가지고 있다. Endpoint의 상태는 다음과 같이 확인이 가능하다
1
2
3
4
5
kubectl get endpoints
kubectl get ep #줄여서
# redis Endpoint 확인
kubectl describe ep/redis
Service(NodePort) 만들기
NodePort는 클러스터의 모든 노드에 포트를 오픈한다. 여러개의 노드가 있다면 아무 노드로 접근해도 지정한 pod으로 접근할 수 있다.
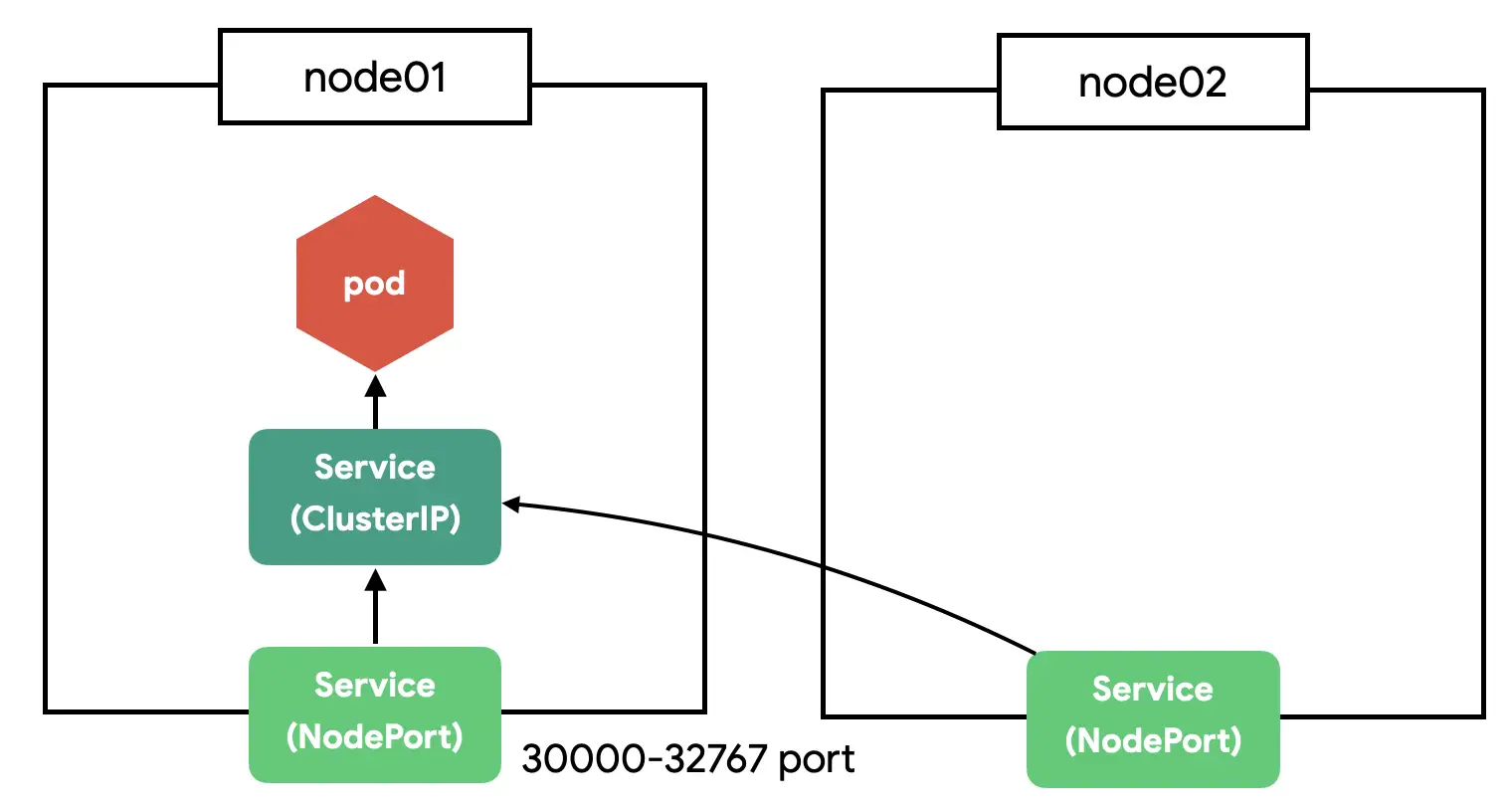
참고로 NodePort는 ClusterIP의 기능을 기본으로 포함한다.
Service(LoadBalancer) 만들기
NodePort의 단점은 노드가 사라졌을 때 자동으로 다른 노드를 통해 접근이 불가능하다는 점이다. 예를 들어 3개의 노드가 있다면 3개 중에 아무 노드로 접근해도 NodePort로 연결할 수 있지만 어떤 노드가 살아있는지는 알수가 없다.
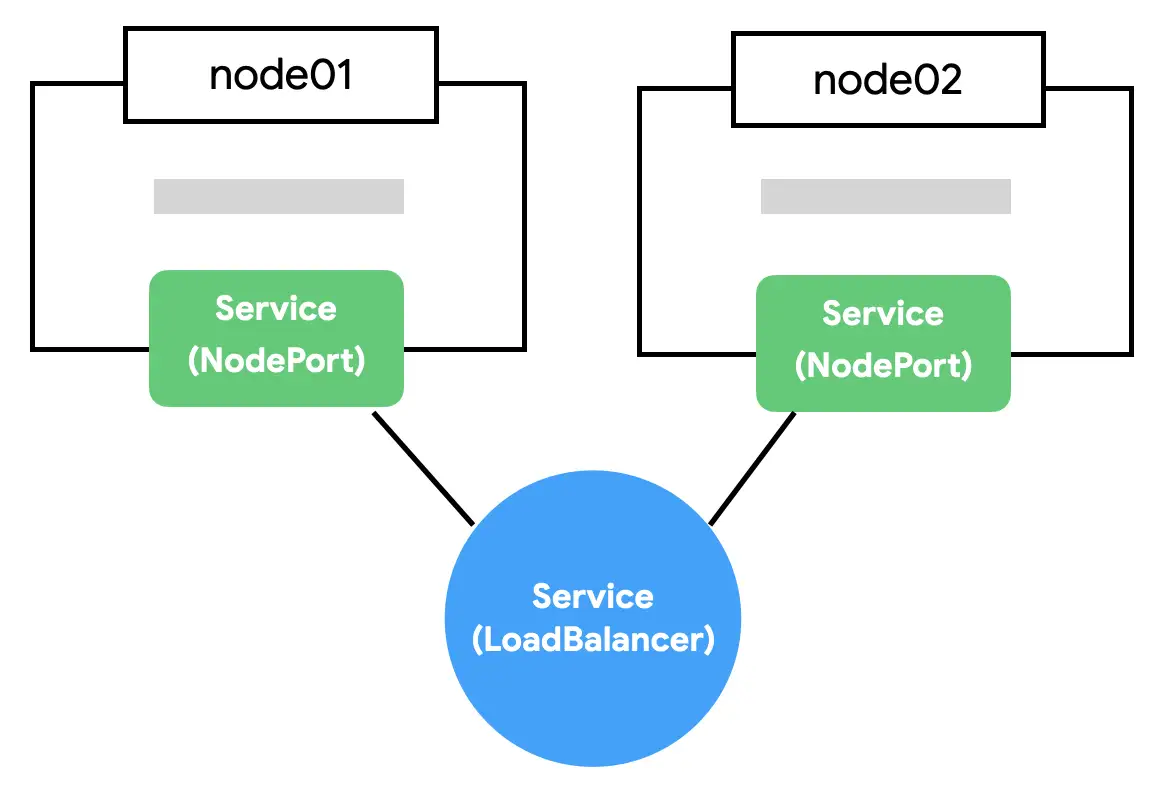
자동으로 살아있는 노드에 접근하기 위해 모든 노드를 바라보는 Load Balancer가 필요하다. 브라우저는 NodePort에 직접 요청을 보내는 것이 아니라 LoadBalancer에 요청하고 LoadBalancer가 알아서 살아있는 노드에 접근하면 NodePort의 단점을 없앨 수 있다.
ClusterIP vs NodePort vs LoadBalancer
- ClusterIP : 클러스터 내부에서 접근 가능한 ip를 염.
- ip는 자동으로 생성되고, port는 selector로 걸린 pod의 targetPort를 port로 지정한 값으로 염.
- 클러스터 내부의 Pod에서만 접근 가능
- ClusterIP의 name을 도메인으로 사용할 수 있음.
- 로드밸런서의 역할도 제공한다.
- NodePort : 클러스터 외부에서 접근 가능한 포트를 염
- selector로 걸린 pod의 targetPort를 port로 지정한 값으로 ClusterIP를 염. 외부로는 nodePort로 지정한 값으로 염.
- NodePort는 기본적으로 ClusterIP의 기능을 포함함. 따라서 클러스터 내부의 pod들은, NodePort로 연 port를, NodePort를 생성할 때 지정되는 ClusterIP를 통해 접근가능하다.
- 분산 노드 애플리케이션에서는 오토스케일링을 이유로 노드들의 네트워크 환경이 동적으로 변한다면, 서비스 디스커버리와 같은 방법으로 클라이언트에서 노드들의 네트워크 엔드포인트르 관리해야함. -> 로드 밸런서로 해결
- LoadBalancer : NodePort 기능 + 살아있는 노드를 자동으로 찾아 요청을 전달함.
- selector로 걸린 pod의 targetPort를 port로 지정한 값으로 염. 외부로는 nodePort로 지정한 값으로 염.
- LoadBalancer는 기본적으로 NodePort의 기능을 포함함.
주의
실전에서 NodePort와 LoadBalancer는 제한적으로 사용한다. 보통 웹 어플리케이션을 배포하면 80 또는 443 포트만 사용하고 하나의 포트에서 여러 개의 서비스를 도메인이나 경로에 따라 다르게 설정하기 때문이다. 이 부분은 Ingress에서 처리할 수 있다.
Ingress
하나의 클러스터에서 여러가지 서비스를 운영한다고 해보자. 이때 NodePort를 사용하여 서비스 개수만큼 포트를 열고 사용자에게 어떤 포트인지 알려주는 방법은 유저 경험에 좋지 않다.
좋은 방법은 같은 포트 아래에서 각 서비스를 path로 구분하는 방법이고, Ingress 사용해 구현한다.
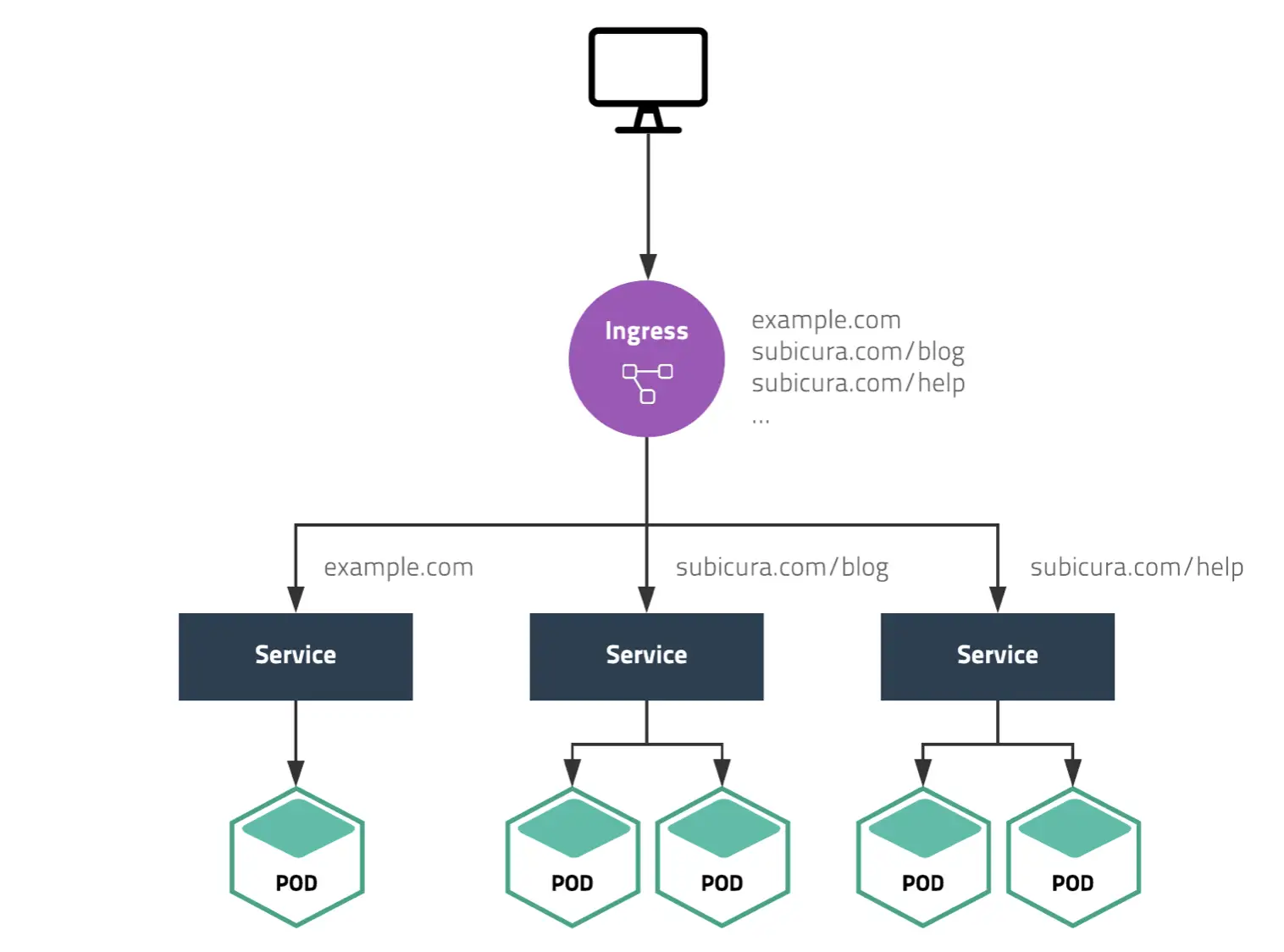
Ingress 만들기
Ingress 생성 흐름
Ingress Controller는Ingress변화를 체크Ingress Controller는 변경된 내용을Nginx에 설정하고 프로세스 재시작
YAML로 만든 Ingress 설정을 단순히 nginx 설정으로 바꾸는 과정을 Ingress Controller가 자동으로 해주는 것이다.
Ingress는 도메인, 경로만 연동하는 것이 아니라 요청 timeout, 요청 max size 등 다양한 프록시 서버 설정을 할 수 있다.
Volume
MySQL과 같은 데이터베이스는 데이터가 유실되지 않도록 반드시 별도의 저장소에 데이터를 저장하고, 컨테이너를 새로 만들 때 이전 데이터를 가져와야한다.
쿠버네티스는 Volume을 사용하여 컨테이너의 디렉토리를 외부 저장소와 연결하고 다양한 플러그인을 지원하여 흔히 사용하는 대부분의 스토리지를 별도 설정없이 사용할 수 있다.
Volume(empty-dir) 만들기
empty-dir은 같은 pod 안에 속한 컨테이너 간 디렉터리를 공유하는 방법으로 보통 사이드카 패턴에서 사용한다. 예를들어 특정 컨테이너에서 생성되는 로그 파일을 별도의 컨테이너가 수집할 수 있다.
![]()
아래 예시는 app 컨테이너는 /var/log/example.log에 로그 파일을 만들고, sidecar 컨테이너는 해당 로그파일을 처리하도록 하는 예시다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
apiVersion: v1
kind: Pod
metadata:
name: sidecar
spec:
containers:
- name: app
image: busybox
args:
- /bin/sh
- -c
- >
while true;
do
echo "$(date)\n" >> /var/log/example.log;
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: sidecar
image: busybox
args: [/bin/sh, -c, "tail -f /var/log/example.log"]
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
다음 명령어로 테스트해볼수 있다.
1
2
3
4
kubectl apply -f empty-dir.yml
# sidecar 로그 확인
kubectl logs -f sidecar -c sidecar
hostpath
호스트(node) 디렉터리를 컨테이너 디렉터리에 연결하는 방법이다.
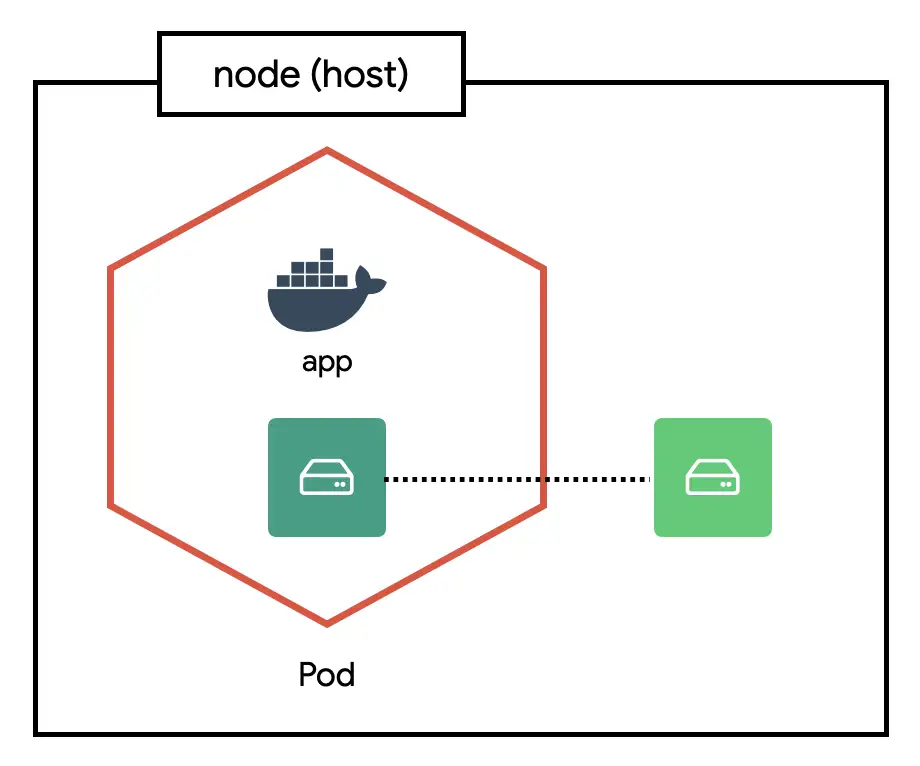
아래 예시는 호스트의 /var/log를 컨테이너의 /host/var/log 디렉터리로 마운트한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
apiVersion: v1
kind: Pod
metadata:
name: host-log
spec:
containers:
- name: log
image: busybox
args: ["/bin/sh", "-c", "sleep infinity"]
volumeMounts:
- name: varlog
mountPath: /host/var/log
volumes:
- name: varlog
hostPath:
path: /var/log
아래 명령어로 마운트된 디렉터리를 확인할 수 있다.
1
2
3
4
5
kubectl apply -f hostpath.yml
# 컨테이너 접속 후 /host/var/log 디렉토리를 확인
kubectl exec -it host-log -- sh
ls -al /host/var/log
ConfigMap
컨테이너에서 설정 파일을 관리하는 방법은 이미지를 빌드할 때 복사하거나, 컨테이너를 실행할 때 외부 파일을 연결하는 방법이 있다.
쿠버네티스는 ConfigMap으로 설정을 관리한다.
ConfigMap을 만드는 방법을 다음 세가지가 있다. 실습
- ConfigMap 파일 직접 생성
- env 파일로 생성
- YAML 파일로 생성
ConfigMap은 컨테이너에서 volume으로 마운트하여 파일을 가져오는 방식으로 사용한다. 하지만 volume이 아닌 환경변수로 설정할 수도 있다. 이때는 다음과 같이 환경 변수를 작성하는 곳에 configMap을 키로 연결하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
apiVersion: v1
kind: Pod
metadata:
name: alpine-env
spec:
containers:
- name: alpine
image: alpine
command: ["sleep"]
args: ["100000"]
env:
- name: hello
valueFrom:
configMapKeyRef:
name: my-config
key: hello
Secret
쿠버네티스에서 비밀번호, SSH 인증, TLS Secret와 같은 보안 정보를 관리하는 방법으로, ConfigMap과 유사하지만, 보안 정보를 관리하기 위해 Secret을 별도로 제공한다.
ConfigMap와의 차이점은 데이터가 base64로 저장되는 거 말고는 거의 없다.
주의
Secret은 암호화 되지 않는다. 있는 정보를 그대로 저장하며, etcd에 접근이 가능하면 누구나 저장된 Secret을 확인할 수 있다. vault와 같은 외부 솔루션을 사용하여 보안을 강화할 수 있다.
Secret 만들기
출처
https://subicura.com/k8s/